Big Data Analysis with Apache Spark
A project to analyze web crawl data with Apache Spark. The analysis focuses on wikipedia images data.

Big Data Analysis with Apache Spark
Introduction
During the Big Data course at Radboud University, I learned to use Apache Spark for large-scale data analysis and Spark Structured Streaming for real-time data processing.
In this presentation, I will introduce Apache Spark, Spark Structured Streaming, and explain how I used Spark to analyze web crawl data, with a focus on image data from Wikipedia.
Project Repository:
What is Big Data?
Big Data refers to vast amounts of structured and unstructured data generated daily. The significance lies not just in the volume but in how businesses analyze and derive insights from it to make informed decisions. Big Data analytics allows organizations to uncover trends, make predictions, and enhance strategies.
Web Crawling
Web crawling is the automated process of collecting data from websites. It is primarily used by search engines to index web pages, making content searchable. These automated bots, also known as web crawlers or spiders, systematically browse the internet, collecting information such as URLs, titles, and content.
Web Crawl Data
Web crawl data is a collection of the data harvested by web crawlers. It can include elements such as URLs, metadata, and page content. This type of data is useful for search engine optimization, web analytics, and data mining.
In this project, I analyzed web crawl data from Wikipedia to extract information related to images. The data, typically stored in a distributed file system like HDFS (Hadoop Distributed File System), was stored in the University’s Cluster using HDFS for distributed storage.
Apache Spark
Apache Spark is a distributed computing system designed for large-scale data processing. It offers a unified framework for handling data parallelism and fault tolerance.
Spark supports high-level APIs in Java, Scala, Python, and R, making it accessible to various programming communities. Its optimized execution engine supports general execution graphs, making it efficient for a wide range of tasks. Some of the key components of Spark include:
Spark SQL: For processing structured data using SQL-like queries.MLlib: A library for scalable machine learning.GraphX: For graph processing and analysis.Spark Streaming: For real-time data processing.
In this project, I used Spark to analyze Wikipedia’s web crawl image data, focusing on the distributed processing capabilities of Spark and leveraging Spark Structured Streaming for handling continuous data streams in real time.
Spark Basics
Spark Architecture
Spark is built around the concept of a resilient distributed dataset (RDD). What is RDD ?
- RDD is a fault-tolerant collection of elements that can be operated on in parallel.
- RDDs can be created from Hadoop InputFormats (such as HDFS files) or by transforming other RDDs.
- RDDs support two types of operations: transformations, which create a new dataset from an existing one, and actions, which return a value to the driver program after running a computation on the dataset.
- RDDs are lazily evaluated, meaning that their values are not computed until they are used in an action.
RDD is the fundamental data structure of Spark. It is an immutable distributed collection of objects. Each dataset in Spark is split into logical partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes.
The following code snippet shows how to create an RDD from a list of numbers and then perform a transformation on it:
1
2
3
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
val result = distData.map(x => x * x)
In this example, sc.parallelize(data) creates an RDD from the data array. The map transformation is then applied to the RDD to square each element.
Spark Session
The entry point to programming Spark with the Dataset and DataFrame API. A SparkSession can be used to create DataFrame, register DataFrame as tables, execute SQL over tables, cache tables, and read parquet files.
1
2
3
4
5
6
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
Then you can use the spark object to create DataFrames and perform operations on them. For example:
1
2
val df = spark.read.json("examples/src/main/resources/people.json")
df.show()
You can also run SQL queries over tables that you register with the spark object. For example:
1
2
3
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
Spark Structured Streaming
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. It allows you to process real-time data streams using high-level abstractions like DataFrames and SQL queries. Structured Streaming provides exactly-once semantics and fault tolerance out of the box. Here are some key features of Structured Streaming:
- Continuous Processing: Structured Streaming allows you to process data continuously, enabling real-time analytics.
- Fault Tolerance: Structured Streaming provides fault tolerance and exactly-once semantics, ensuring that each record is processed exactly once.
- Integration with Spark SQL: You can use SQL queries and DataFrame operations to process streaming data, making it easy to work with real-time data.
During my course, I learned to use Spark Structured Streaming to process streaming data in real time. Here is an example of a Structured Streaming application that reads streaming data from a socket, processes it, and writes the results to the console:
Click to expand the code snippet
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
package org.rubigdata
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.scalalang.typed
object RUBigDataApp {
def main(args: Array[String]) {
val spark = SparkSession.builder.appName("RUBigDataApp").getOrCreate()
import spark.implicits._
spark.sparkContext.setLogLevel("WARN")
val regex = "^([A-Z].+) ([A-Z].+) was sold for (\\d+)gp$"
val socketDF = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
val sales = socketDF
.select(
regexp_extract($"value", regex, 2) as "tpe",
regexp_extract($"value", regex, 3).cast(IntegerType) as "price",
regexp_extract($"value", regex, 1) as "material"
)
.as[RuneData]
sales.createOrReplaceTempView("sales")
val item9850 = spark.sql("SELECT tpe, material, price " +
"FROM sales " +
"WHERE price >= 9840 AND price <= 9850 " +
"GROUP BY tpe, material, price " +
"HAVING price = 9850")
val query = item9850
.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
spark.stop()
}
}
case class RuneData(tpe: String, price: Int, material: String)
This code comes from Assignment 5 of the Big Data course at Radboud University, where we had to implement a Spark Structured Streaming application to process streaming data. In this example, we read streaming data from a socket and extract information about sales of items. We then filter the data to find items that were sold for a price between 9840 and 9850 gp. The results are written to the console. The awaitTermination method is called to keep the streaming query running until the user interrupts it. Finally, we stop the Spark session. We use the RuneData case class to define the schema of the data we are working with.
Final Project: Analyzing Wikipedia Image Data
Project Overview
For the final project of the Big Data course, I analyzed web crawl data from Wikipedia to extract information related to images. The data was stored in the University’s cluster using HDFS for distributed storage. In this project, I used Apache Spark to process the data and extract insights from it. The analysis focused on computing statistics related to the images, such as the number of images per page, the average image size, the biggest image etc.
Sinle Warc File Analysis
Starting with a Word Count Example
The first important step before going through the cluster was to learn how to analyse WARC files. To do this I have done some single WARC file analysis on zeppelin notebook on the big-data container. I downloaded a WARC files from the url https://en.wikipedia.org/wiki/Multilingualism thanks to the following bash command, we are going to use this small WARC file to create our first programs:
[ ! -f multilingualism.warc.gz ] && wget -r -l 3 "https://en.wikipedia.org/wiki/Multilingualism" --delete-after --no-directories --warc-file="multilingualism" || echo Most likely, multilingualism.warc.gz already exists
To get started with Spark, I implemented a simple word count example. The goal was to count the frequency of words in a WARC file containing Wikipedia data. The code snippet below shows how I read the WARC file, extracted the text content, tokenized the words, and counted their occurrences.
Click to expand the Word Count Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import org.apache.spark.sql.SparkSession
import org.jsoup.Jsoup
val spark = SparkSession.builder()
.appName("WARC Analysis")
.getOrCreate()
val warcData = spark.sparkContext.wholeTextFiles(warcfile)
// Extract the text content from the WARC data and remove HTML tags
val textContent = warcData.flatMap { case (_, content) =>
val lines = content.split("\n")
val header = lines.take(2) // Header lines
val htmlContent = lines.drop(2).mkString("\n") // HTML content
val doc = Jsoup.parse(htmlContent)
val text = doc.text()
val cleanedText = text.replaceAll("\\W+", " ") // Remove non-word characters except spaces
cleanedText.split("\\s+")
}
val wordCount = textContent
.map(word => (word.toLowerCase, 1))
.reduceByKey(_ + _)
.sortBy(_._2, ascending = false)
wordCount.take(5).foreach(println)
spark.stop()
1
2
3
4
5
(the, 462)
(disallow, 453)
(wiki, 422)
(in, 338)
(of, 333)
In this example, I read the WARC file using spark.sparkContext.wholeTextFiles(warcfile) and extracted the text content from the HTML data. I used the Jsoup library to parse the HTML content and remove the HTML tags. I then tokenized the words, converted them to lowercase, and counted their occurrences using the reduceByKey transformation. Finally, I sorted the word count in descending order and printed the top 5 words.
This example helped me understand the basics of working with Spark on WARCs and text data.
Wikipedia Image Analysis
Now let’s start to play with the images. In Wikipedia, the size of the images on the website are defined using the height and width attributes. The images are displayed with the following html format:
1
<img src=”image_link”, some_other_things = something, width = value, height = value, >
Then we can use a regular expression pattern to catch the element of the WARC files that correspond to this format in order to extract the images. We can use the following regular expression pattern:
1
val pattern = """(?i)<img[^>]*src=['"]([^'"]+)[^>]*\swidth\s*=\s*['"](\d+)['"][^>]*\sheight\s*=\s*['"](\d+)['"][^>]*>""".r
Here is a program that analyses all the images (corresponding to the regex) of a WARC file:
Click to expand the code snippet
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("WARC Image Analysis")
.getOrCreate()
val sc = spark.sparkContext
val warcFile = sc.wholeTextFiles("file:///opt/hadoop/rubigdata/multilingualism.warc.gz")
// Extract image URLs and compute the arbitrary size for each image
val imageData = warcFile.flatMap { case (_, content) =>
val pattern = """(?i)<img[^>]*src=['"]([^'"]+)[^>]*\swidth\s*=\s*['"](\d+)['"][^>]*\sheight\s*=\s*['"](\d+)['"][^>]*>""".r
pattern.findAllMatchIn(content).map { m =>
val url = m.group(1)
val height = m.group(2).toInt
val width = m.group(3).toInt
val arbitrarySize = height * width
(url, arbitrarySize)
}
}
// Compute the total number of images
val numImages = imageData.count()
// Compute the mean arbitrary size
val meanArbitrarySize = imageData.map(_._2).mean()
// Print the total number of images and the mean arbitrary size
println(s"Total number of images: $numImages")
println(s"Mean arbitrary size: $meanArbitrarySize")
spark.stop()
1
2
Total number of images: 31
Mean arbitrary size: 24877.967
To improve our code we could add the following features:
- Select images that are only part of Wikipedia website thanks to a filter on the URL
- Search for the biggest image (in number of pixels displayed on the website)
- Find the url of the website that contains the biggest image to see how it is displayed
- Using the library
HadoopConcatgzto read WARC files in a more efficient way
Here is a code that implement those features:
Click to expand the code snippet with the new features
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
import org.apache.spark.sql.SparkSession
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.fs.FileSystem
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat
import de.l3s.concatgz.io.warc.{WarcGzInputFormat, WarcWritable}
import de.l3s.concatgz.data.WarcRecord
import org.apache.spark.SparkConf
case class ImageData(pageUrl: String, imageUrl: String, size: Int)
val sparkConf = new SparkConf()
.setAppName("RUBigDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[WarcRecord]))
val spark = SparkSession.builder.config(sparkConf).getOrCreate()
import spark.implicits._
val fs = FileSystem.get(spark.sparkContext.hadoopConfiguration)
val warcFile = "/opt/hadoop/rubigdata/multilingualism.warc.gz"
val sc = spark.sparkContext
val warcs = sc.newAPIHadoopFile(
warcFile,
classOf[WarcGzInputFormat], // InputFormat
classOf[NullWritable], // Key
classOf[WarcWritable] // Value
).cache()
// Filter for URLs that contain 'wikipedia.org'
val filteredWarcs = warcs.filter { case (_, wr) =>
val header = wr.getRecord.getHeader
header.getHeaderValue("WARC-Type") == "response" &&
header.getUrl.contains("wikipedia.org")
}
val imageData = filteredWarcs.mapPartitions { iter =>
iter.flatMap { case (_, wr) =>
val content = wr.getRecord.getHttpStringBody
val pageUrl = wr.getRecord.getHeader.getUrl
val pattern = """(?i)<img[^>]*src=['"]([^'"]+)[^>]*\swidth\s*=\s*['"](\d+)['"][^>]*\sheight\s*=\s*['"](\d+)['"][^>]*>""".r
pattern.findAllMatchIn(content).map { m =>
val imageUrl = m.group(1)
val height = m.group(2).toInt
val width = m.group(3).toInt
val arbitrarySize = height * width
ImageData(pageUrl, imageUrl, arbitrarySize)
}
}
}
val numImages = imageData.count()
val meanArbitrarySize = imageData.map(_.size).mean()
// Search for the largest image in imageData
val largestImage = imageData.reduce((a, b) => if (a.size > b.size) a else b)
println(s"Total number of images: $numImages")
println(s"Mean arbitrary size: $meanArbitrarySize")
println(s"Largest image URL: ${largestImage.imageUrl} with size: ${largestImage.size}")
println(s"Webpage URL: ${largestImage.pageUrl}")
spark.stop()
1
2
3
4
Total number of images: 31
Mean arbitrary size: 24877.967
Largest image URL: https://upload.wikimedia.org/wikipedia/commons/thumb/7/75/339px-POla_07.jpg with size: 86106
Webpage URL: https://en.wikipedia.org/wiki/Multilingualism
Standalone application & Running on the Cluster
To run the Spark application as a standalone application, you need to package your code into a JAR file and submit it to the Spark cluster using the spark-submit command. The JAR file should contain all the necessary dependencies and resources required to run the application. You can use tools like sbt assembly to create a fat JAR that includes all dependencies. The spark-submit command allows you to specify the main class of your application, the JAR file, and other configuration options. The application will be executed on the Spark cluster, leveraging its distributed computing capabilities.
Run on the Cluster
Finally, I ran the Spark application on the University’s cluster to analyze the whole dataset of WARC files. The cluster provided a distributed environment to process the data in parallel, leveraging the computing power of multiple nodes. The analysis focused on extracting image data from the WARC files and computing statistics related to the images.
Here is the final code that I used to analyze the whole dataset of WARC files on the cluster:
Click to expand the code snippet
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
package org.rubigdata
import org.apache.hadoop.io.{NullWritable}
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat
import de.l3s.concatgz.io.warc.{WarcGzInputFormat,WarcWritable}
import de.l3s.concatgz.data.WarcRecord
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
case class ImageData(pageUrl: String, imageUrl: String, size: Int)
case class AggResult(count: Long, totalSize: Long, largestImage: ImageData)
object RUBigDataApp {
def main(args: Array[String]) {
// Overriding default settings
val sparkConf = new SparkConf()
.setAppName("RUBigDataApp")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.registerKryoClasses(Array(classOf[WarcRecord]))
val spark = SparkSession.builder.config(sparkConf).getOrCreate()
import spark.implicits._
// Getting the FileSystem object
val fs = FileSystem.get(spark.sparkContext.hadoopConfiguration)
// List and sort the files, and take all the WARC files
val warcDirPath = new Path("hdfs:///single-warc-segment")
val warcFiles = fs.listStatus(warcDirPath)
.filter(fileStatus => fileStatus.getPath.getName.endsWith(".warc.gz")) // filter for .warc.gz files
.sortBy(_.getPath.getName) // sort them
.map(_.getPath.toString) // convert to string
val sc = spark.sparkContext
val warcs = sc.union(warcFiles.map(file => sc.newAPIHadoopFile(
file,
classOf[WarcGzInputFormat], // InputFormat
classOf[NullWritable], // Key
classOf[WarcWritable] // Value
))).cache()
val filteredWarcs = warcs.filter { case (_, wr) =>
val header = wr.getRecord.getHeader
header.getHeaderValue("WARC-Type") == "response" &&
header.getUrl.contains("wikipedia.org")
}
val imageData = filteredWarcs.mapPartitions { iter =>
iter.flatMap { case (_, wr) =>
val content = wr.getRecord.getHttpStringBody
val pageUrl = wr.getRecord.getHeader.getUrl
val pattern = """(?i)<img[^>]*src=['"]([^'"]+)[^>]*\swidth\s*=\s*['"](\d+)['"][^>]*\sheight\s*=\s*['"](\d+)['"][^>]*>""".r
pattern.findAllMatchIn(content).map { m =>
val imageUrl = m.group(1)
val height = m.group(2).toInt
val width = m.group(3).toInt
val arbitrarySize = height * width
ImageData(pageUrl, imageUrl, arbitrarySize)
}
}
}
// Aggregate function to compute count, total size, and largest image in a single pass
val aggResult = imageData.aggregate(AggResult(0L, 0L, ImageData("", "", 0)))(
// SeqOp: Update the accumulator with each element in the partition
(acc, imgData) => AggResult(
acc.count + 1,
acc.totalSize + imgData.size,
if (imgData.size > acc.largestImage.size) imgData else acc.largestImage
),
// CombOp: Merge accumulators from different partitions
(acc1, acc2) => AggResult(
acc1.count + acc2.count,
acc1.totalSize + acc2.totalSize,
if (acc1.largestImage.size > acc2.largestImage.size) acc1.largestImage else acc2.largestImage
)
)
val numImages = aggResult.count
val meanArbitrarySize = if (numImages > 0) aggResult.totalSize.toDouble / numImages else 0.0
val largestImage = aggResult.largestImage
// Print the results
println(s"Total number of images: $numImages")
println(s"Mean arbitrary size: $meanArbitrarySize")
println(s"Largest image URL: ${largestImage.imageUrl} with size: ${largestImage.size}")
println(s"Webpage URL: ${largestImage.pageUrl}")
}
}
I compiled the code with sbt assembly and submitted the jar file to the cluster with spark-submit --class org.rubigdata.RUBigDataApp target/scala-2.12/RUBigDataApp-assembly-1.0.jar.
The job ran on the cluster and provided the following output:
1
2
3
4
Total number of images: 852057
Mean arbitrary size: 8036.973536487572
Largest image URL: //upload.wikimedia.org/wikipedia/commons/thumb/8/83/Bataan_in_Philipines.svg/4200px-Bataan_in_Philipines.svg.png with size: 25641000
Webpage URL: https://ceb.wikipedia.org/wiki/Bataan
The analysis of the whole dataset revealed that there were 852,057 images in the WARC files, with a mean arbitrary size of 8036.97. The largest image had a size of 25,641,000 pixels and was displayed on this webpage.
Thanks to Wayback Machine, we can see the webpage as it was during the crawl. The image is displayed below:
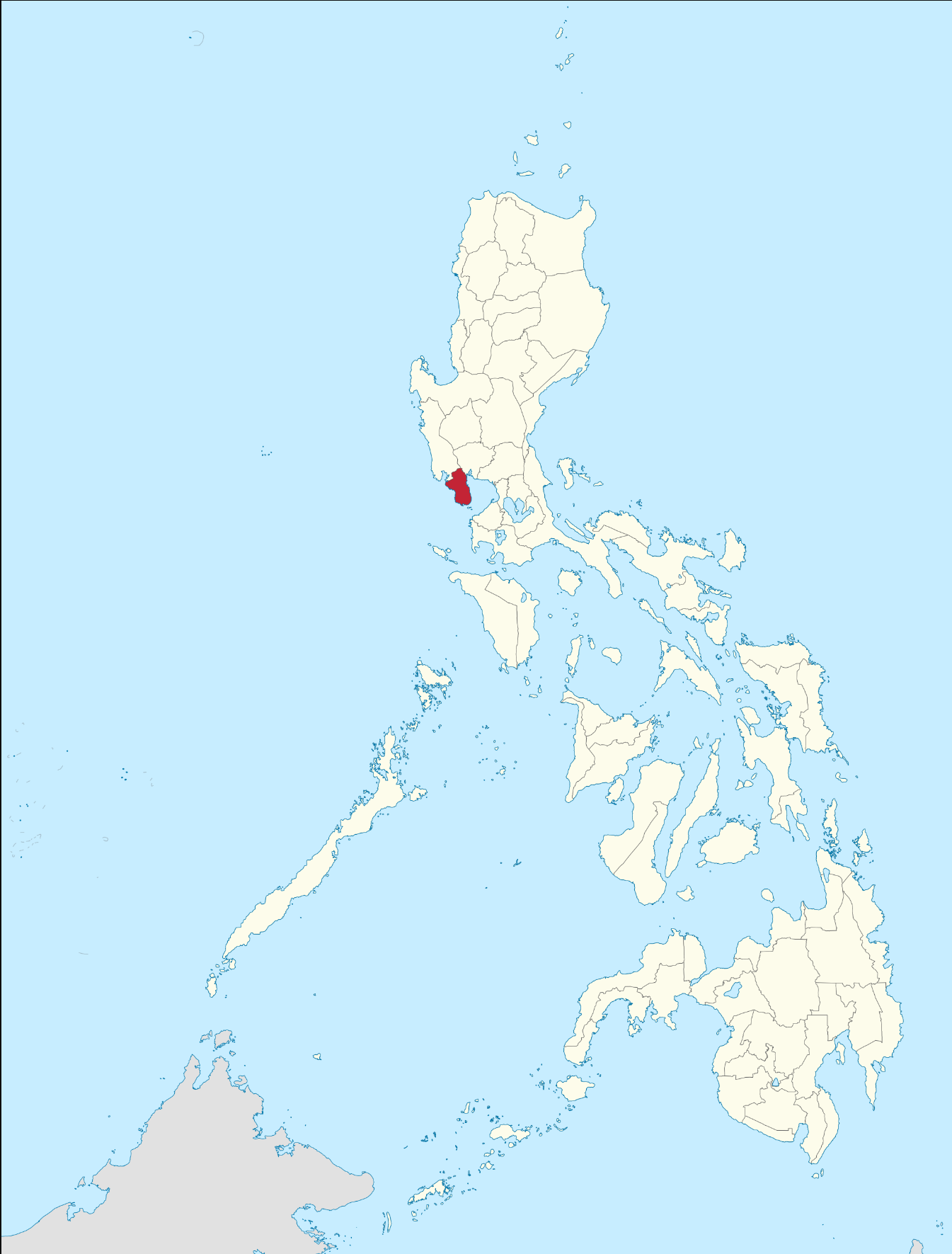
This image was the largest one found in the dataset, with a size of 25,641,000 pixels. It represents the province of Bataan (in red) in the Philippines.
Performances
The analysis of the whole dataset was a computationally intensive task that required processing a large amount of data. By running the Spark job on the cluster, I was able to leverage the distributed computing capabilities of the cluster to process the data in parallel. This significantly reduced the processing time and improved the performance of the analysis.
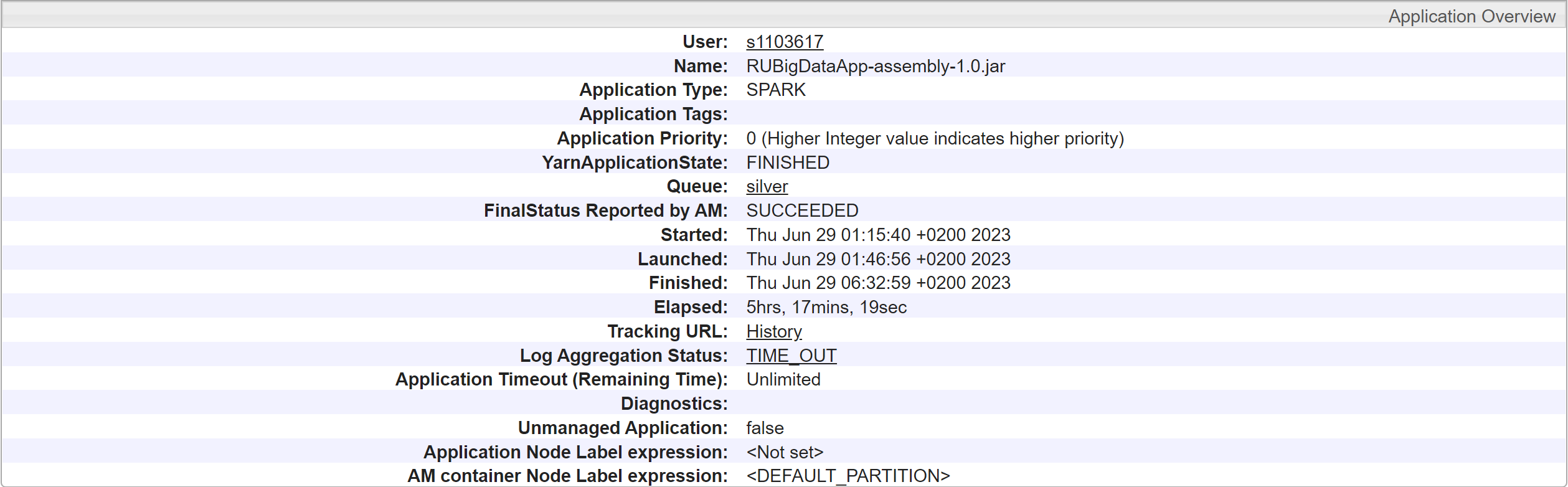
The application ran for 4 hours and 46 minutes, processing a total of 700 Go of unstructured data.
Conclusion
In this project, I used Apache Spark to analyze web crawl data from Wikipedia and extract information related to images. The analysis focused on computing statistics related to the images, such as the number of images per page, the average image size, and the largest image. By leveraging the distributed computing capabilities of Spark and running the analysis on the University’s cluster, I was able to process the data efficiently and derive insights from it. The project provided valuable hands-on experience with big data analysis and distributed computing using Apache Spark.
The analysis of the web crawl data demonstrated the power of Spark for processing large-scale datasets and extracting meaningful information from them. The ability to work with structured and unstructured data, perform complex computations, and derive insights from the data makes Spark a valuable tool for big data analytics. The project also highlighted the importance of distributed computing for handling large volumes of data and the benefits of running Spark applications on a cluster to improve performance and scalability.